Eravamo ancora all’inizio di questa pandemia e già ci si interrogava su come Big Data e Sanità potessero lavorare insieme per fronteggiare questo nemico invisibile. Era marzo 2020, infatti, quando avevo già affrontato questo argomento in un blog post che trovi ancora qui, ma cosa è cambiato dopo quasi due anni?
Tanto, ma anche poco!
Tanto a livello regionale, ma poco a livello nazionale. Il nocciolo della questione infatti risiede proprio nella disomogeneità della gestione dei dati.
Nella puntata di Report dello scorso 03/01/2022 (clicca qui per vederla) viene illustrata molto bene la questione tecnica, ma proviamo a fare un po’ di chiarezza.
Quali sono i problemi principali che impediscono di avere un sistema omogeneo nazionale?
Possiamo individuare 3 macro ostacoli:
- I dati, sia Big Data che Small Data, non sono processati tutti allo stesso modo
- Gli Open Data, cioè i dati aperti delle pubbliche amministrazioni, sono i primi che dovrebbero lavorare verso un linguaggio e un’unità comune. Purtroppo non solo non vengono messi a disposizione in tempo reale, ma quando ci sono parlano “lingue” diverse. Questa è una barriera molto alta per chi dovrebbe poi occuparsi di codificarli e unirli per analizzarli, infatti non c’è ancora nessun organo nazionale che lo fa.
- Il fascicolo sanitario elettronico, che come cittadini conosciamo bene, c’è ed esiste ma in realtà è come se non ci fosse per lo stesso motivo del punto due: non esiste un centro di controllo nazionale responsabile di unire e processare i dati.
Come funziona il processo di analisi dei Big Data nella sanità?
Facciamo quindi un passo indietro e vediamo come funziona un modello basato sull’analisi dei dati.
Un progetto basato su di essi è composto da cinque fasi, una correlata con l’altra, sequenziali e continue.
Il modello da me sviluppato, che rappresenta questi cinque step, si chiama “Data Driven Circle”
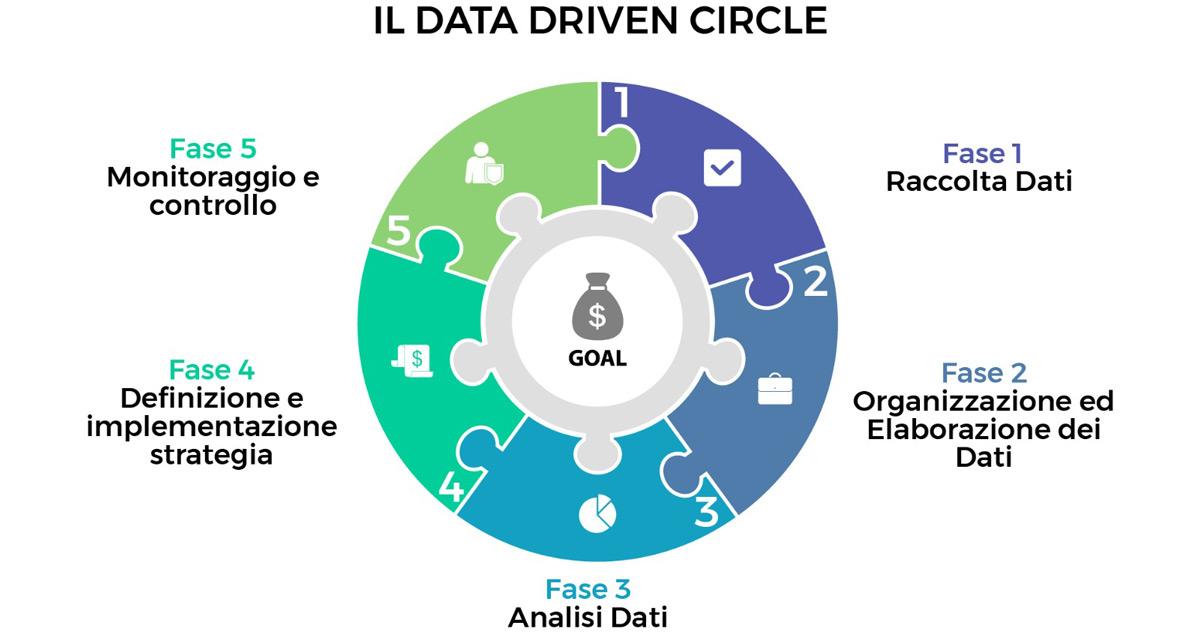
Ogni fase rappresenta un punto di congiunzione tra la precedente e la successiva. Genera un valore aggiunto incrementale che assume una determinata importanza. Le fasi sono disposte a cerchio perché, una volta finita l’ultima fase, il progetto può ricominciare.
Raccolta Dati
Questa fase è il primo anello fondamentale del Data Driven Circle e avviene utilizzando le diverse fonti che si possono avere a disposizione. Nel caso della sanità possono essere: sistemi aziendali interni; open data; i dati delle strutture ospedaliere pubbliche o private etc
Non è importante usare tutte le fonti, anzi, bisogna scegliere quelle giuste per l’obiettivo che ci si è posti. Se la mia analisi Big Data nella sanità ha l’obiettivo di capire l’andamento dei contagi da Covid allora userò delle fonti diverse dall’obiettivo di predire il numero dei posti letti disponibili in terapia intensiva nell’ospedale X.
Si perché se il sistema funzionasse ad oggi, dopo due anni di pandemia, di potrebbe riuscire a predire quello che avverrà nell’immediato futuro.
Organizzazione ed Elaborazione dei Dati
Questa fase viene realizzata con l’ausilio di algoritmi sempre più automatizzati e predittivi. Proprio per questo l’organizzazione dei dati è basata sulla loro classificazione, sul loro accoppiamento, sulla loro correlazione e sulla loro connettività. L’elaborazione serve per pulirli e renderli più facilmente fruibili all’analista e quindi pronti per la fase successiva.
Il punto cruciale per il nostro SSN è quello di unificare tutte fonti e renderle fruibili all’algoritmo scelto per elaborare i dati. Perché la realtà auspicabile è un Centro di Controllo Nazionale responsabile. Se l’algoritmo “Parla cinese” io devo dargli tutti i dati in cinese, non posso darglieli un po’ in cinese, un po’ in italiano, un po’ in tedesco!
Analisi dei Dati
È a questo punto che si innescano gli analytics. L’algoritmo va ad analizzare i dati, che parlano tutti lo stesso linguaggio e hanno tutti lo stesso formato. Per ottenere le informazioni necessarie e le conoscenze utili ad arrivare all’obiettivo prefissato.
Definizione ed Implementazione della Strategia
In questa fase, le informazioni raccolte nello step precedente vengono razionalizzate e organizzate dal team dedicato al progetto data driven.
Il team deve avere al suo interno alcune figure chiave, come ad esempio un rappresentante del management, un data scientist, un analista etc.
Come puoi intuire le figure che compongono il team possono cambiare a seconda dell’obiettivo che ci si è posti in fase preliminare.
Monitoraggio e Controllo
Con questa fase si chiude il cerchio, ma si ricomincia anche il ciclo. È qui che si analizza la strategia e si verifica che abbia portato i risulti previsti in fase preliminare.
Qui avviene anche la parte di archiviazione e indicizzazione dei dati, che consente all’azienda di crearsi un patrimonio unico e una banca dati sempre più grande.
Inoltre, più si raccolgono dati puliti, ottimizzati e che hanno portato un risultato ottimale, più il modello sviluppato sarà efficiente ogni volta che viene messo in azione.
Come puoi immaginare, ogni fase di analisi Big Data per la sanità nasconde dei sotto elementi che consentono al progetto di lavorare al meglio
Da questo ultimo punto capisci bene che prima si inizia a raccogliere, organizzare e processare i dati con un modello di riferimento unico e prima avremmo un sistema efficiente ed efficace a livello nazionale.
Prima questo verrà fatto prima avremmo una democratizzazione della sanità pubblica eliminando il gap tra le varie regioni.
Un aspetto fondamentale di cui tener conto, ma che spesso viene sottovalutato, è che tale metodo ha un notevole impatto sul know-how dei soggetti pubblici o privati. Basato sulla qualità e sulla quantità dei dati a disposizione è inoltre strettamente connesso al knowledge management. Quel complesso di metodi, strumenti e software, che consentono di individuare e utilizzare al meglio le conoscenze e le esperienze aziendali attraverso anche la loro diffusione e organizzazione. Questo però è l’ennesimo punto cruciale del nostro SSN: ogni azienda sanitaria dovrebbe avere dei manager sanitari capaci e competenti nella digitalizzazione che non consiste nel comprare di nuovi pc!
Alcune regioni, purtroppo, pagano lo scotto di un management sanitario poco avvezzo a questo aspetto portando notevoli problematiche
Quindi è tutto un disastro?
Assolutamente no, in molte nostre regioni il modello del Data Driven Circle non solo è funzionante, ma da ottimi risultati aiutando tantissimo la gestione della pandemia.
Ad esempio il Veneto che ha instituito una piattaforma di Bio-Sorveglianza.
Il sistema parte dai medici di base che ricevono sul proprio cruscotto tutte le analisi che i loro assistiti fanno in qualsiasi presidio sanitario della regione e in tempo reale.
Quindi possono verificare subito lo stato di salute dei pazienti, anche in riferimento al COVID ( positivi, negativizzati e da quanto tempo etc ).
Successivamente questi dati convergono nel database della regione che vengono poi trasmetti alle ASL di competenza (in Veneto sono 9).
Queste hanno tra le altre funzioni, una mappa interattiva che gli permette di verificare che in questo preciso momento in una precisa via della loro zona c’è un caso.
In breve ogni ASL ha il controllo in tempo reale di come si sta muovendo l’epidemia nella loro zona di riferimento
A questo punto gli epidemiologi seguono i casi e rimandano alla regione tutte le informazioni dettagliate (quali sintomi, tempo di comparsa, tempi di guarigione etc) che vengono riunite all’istante in un quadro unico.
Questo permette a livello regionale di verificare i cluster, l’accensione dei focolai, la situazione degli ospedali etc e prendere delle misure cautelative ottimizzando le risorse umane e tecniche.
Vengono dimezzati i disguidi e tempi tecnici per i ricoveri, in poche parole
Si ottiene il miglioramento del processo decisionale e l’ottenimento di feedback in tempo reale, attraverso la realizzazione di operazioni real-time e il miglioramento della situazione sanitaria totale.
Ci sono altri modelli regionali che possono fare scuola, l’autonomia regionale ci ha permesso di arrivare fin qui ed è sacrosanta.
Ora però bisognerebbe chiudere il cerchio istituendo un Centro di Controllo Dati Nazionale che permetta di lavorare con i dati in maniera unitaria.
Questo non solo ottimizzerebbe le risorse economiche, umane e tecniche, ma permetterebbe di prevedere e quindi giocare d’anticipo su molte situazioni.
Grazie anche all’AI ( Intelligenza Artificiale ) oltre a migliorare il sistema di diagnostica anticipando i tempi di diagnosi delle malattie; punto cruciale per salvare molte vite.